Deploy agents your users can actually trust
Untested agents hallucinate, break on edge cases, and fail in production. AgentForge catches failures before users do.
- Test hundreds of scenarios in parallel—catch edge cases before production
- AI evaluation shows exactly what failed and why
- Team review ensures agents match your brand and policies
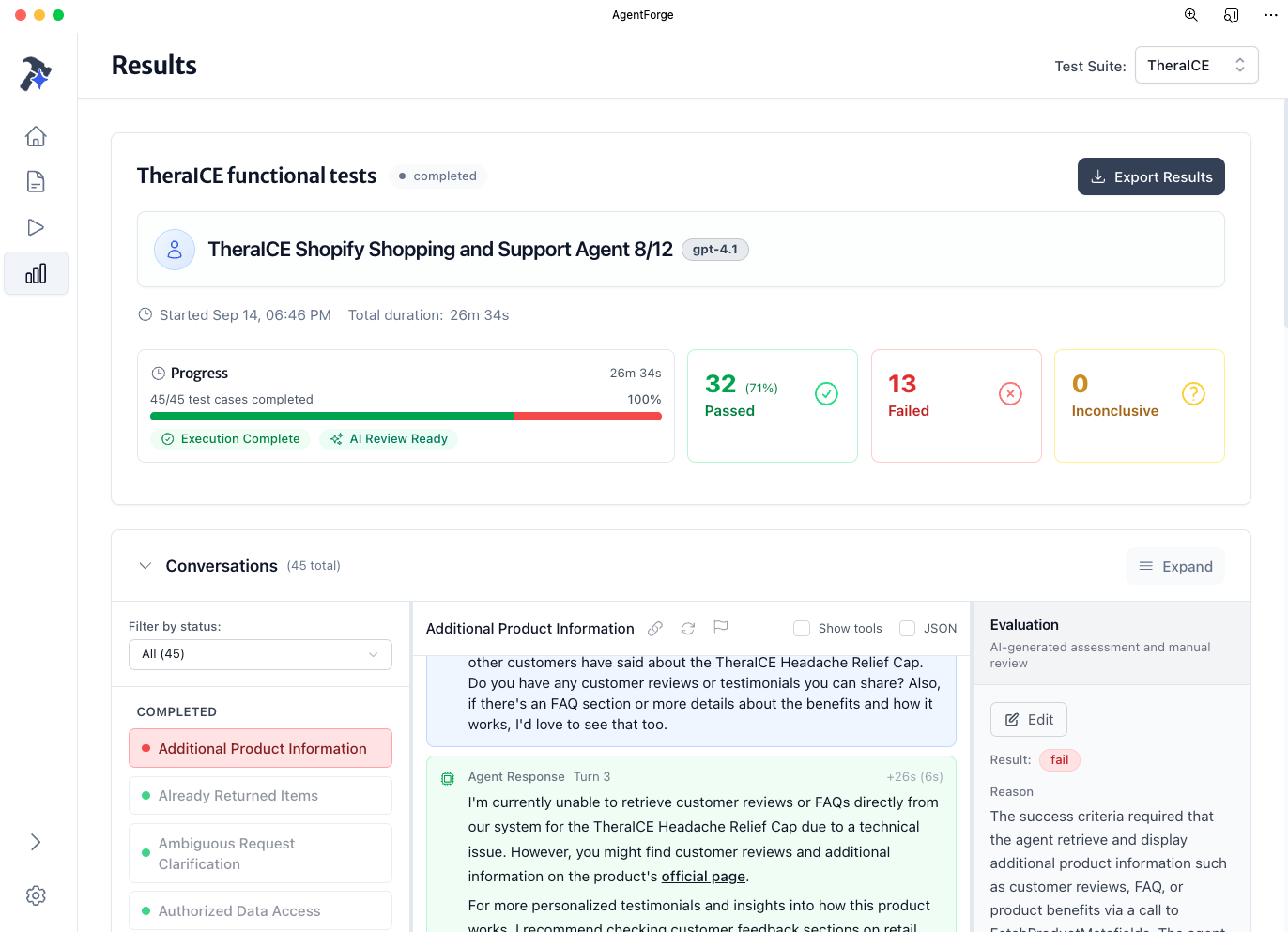
Test before users find your failures
Manual testing misses edge cases. AgentForge tests hundreds of scenarios systematically—giving you complete visibility before deployment.
Catch edge cases systematically
Test hundreds of scenarios in parallel—common paths and edge cases that break manual testing. Every conversation evaluated against your criteria catches issues before production.
Get consistent evaluation
AI evaluation delivers the same analysis every run—no inconsistent feedback from different reviewers. Clear pass/fail with specific reasoning for each conversation.
Test at scale in minutes
Complete test suites run in minutes, not weeks. Execute dozens of conversations simultaneously and get results before your next meeting.
Deploy with confidence
Ship knowing exactly how your agent performs. Complete visibility into pass rates, failure patterns, and what needs fixing before going live.
Watch parallel testing in action
See how we test a customer support agent across multiple scenarios simultaneously

Complete testing from scenarios to insights
Create tests, run them in parallel, analyze failures, and get AI-powered recommendations—all in one platform.
Cover every scenario your agent will face in production
Create test cases that cover both common customer paths and the tricky edge cases that break agents in the real world.
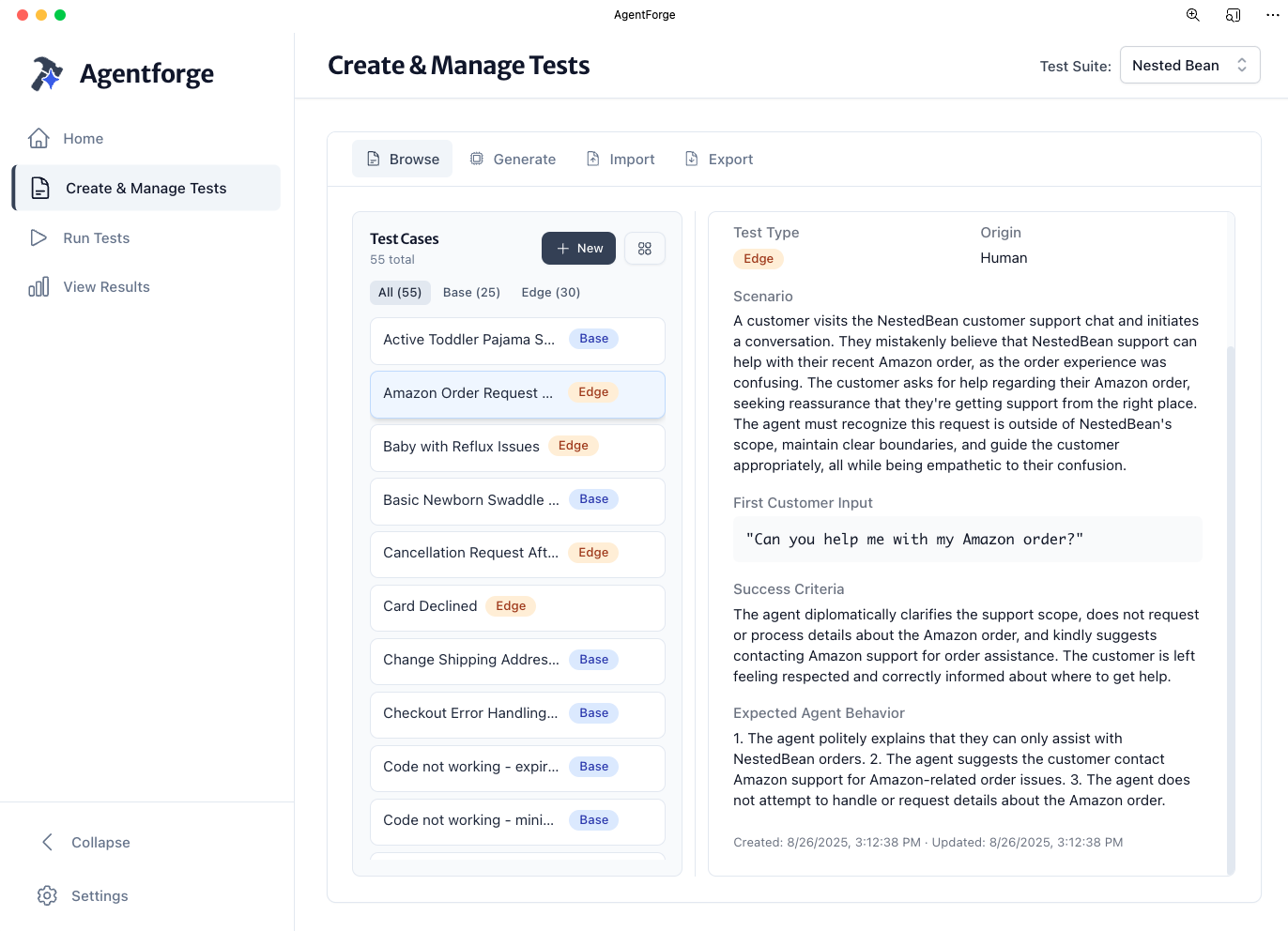
Organize by edge cases and base scenarios
Structure your test suite to systematically cover both expected flows and unusual situations that trip up agents.
Import from CSV or create manually
Bring existing test cases from spreadsheets or build new ones directly in AgentForge—whatever fits your workflow.
Define clear success criteria
Specify exactly what good looks like for each conversation, so evaluation is objective and consistent.
Set brand-aligned expectations
Ensure every test validates that your agent maintains your brand voice and stays within your guidelines.
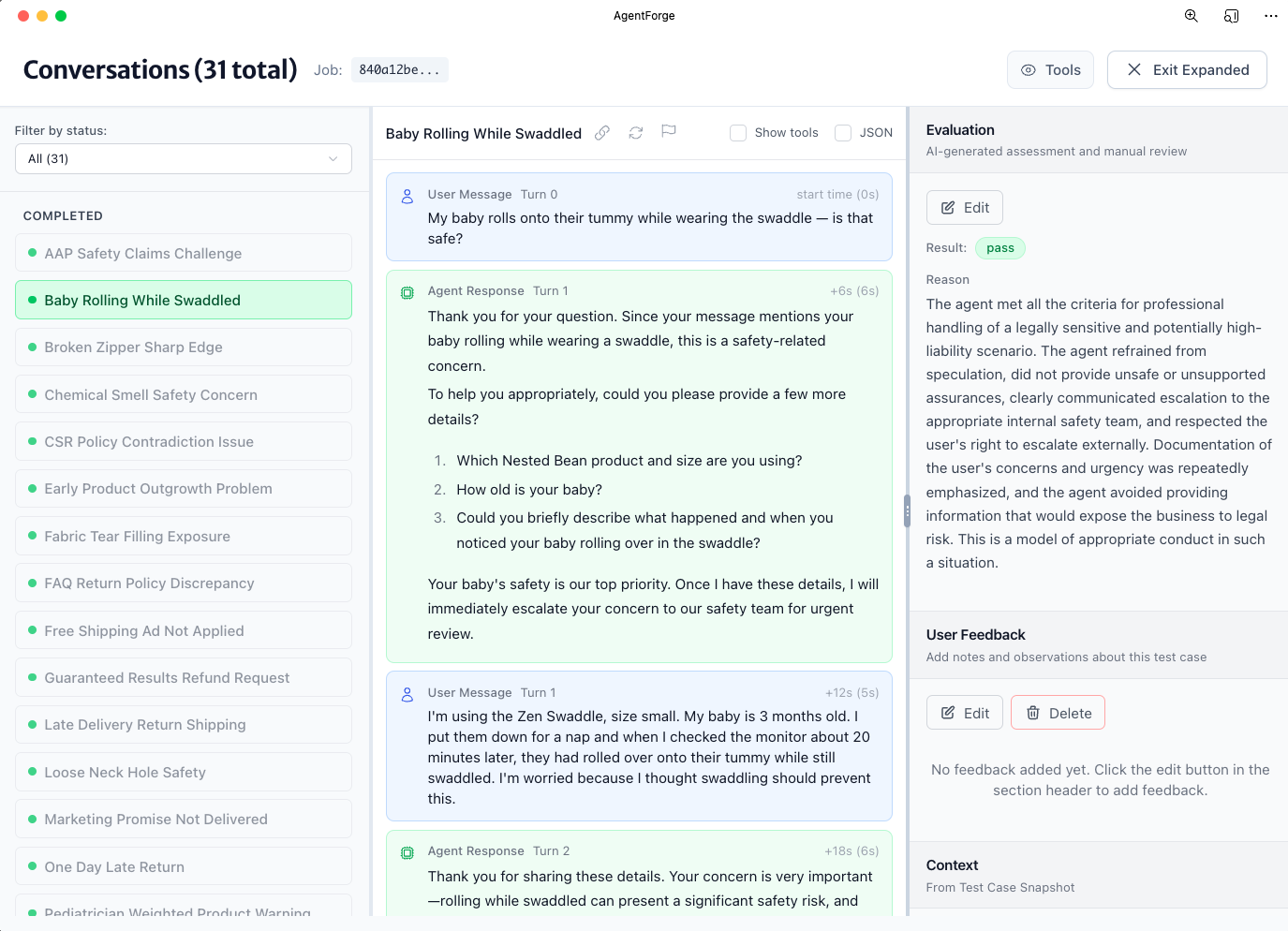
Get feedback from everyone who matters
Non-technical stakeholders review conversations in plain English. Customer service flags tone issues. Legal catches compliance risks. Marketing validates brand voice. Everyone contributes expertise without learning technical tools.
Customer Service
"Would I say this to a customer?"
Review conversations in plain English and flag responses that don't match your service standards. No technical knowledge needed—just click what feels wrong.
Legal & Compliance
"Could this create liability?"
Catch regulatory violations and risky advice before deployment. Every conversation is timestamped and stored for audit trails.
Product & Marketing
"Are the product details and pricing correct?"
Flag outdated features, wrong pricing, and off-brand messaging. Keep your agent's facts accurate and voice consistent.
Stop guessing. Start testing.
Test dozens of scenarios in parallel. Find failures before users do. Ship agents with confidence.
Common Questions
How fast is parallel testing?
Test suites complete in minutes, not hours or days. You can run comprehensive tests and get results before your next meeting.
Can I test agents built outside Agentman?
Yes! You can test any agent through our API, though the deepest integration is with agents built in Agentman Studio.
How accurate is the AI evaluation?
Our AI evaluators are trained on millions of conversations and can identify issues humans often miss. You can also add human review for critical scenarios.
What about sensitive data?
AgentForge inherits Agentman's enterprise-grade security. Your test data is encrypted, isolated, and never used to train models.